수많은 게시물, 뉴스 기사, 상품평 등 엄청난 양의 데이터가 인터넷에 축적되고 있고, 필요에 따라 이러한 데이터를 수집하고 저장해야 하는 일이 많아졌다. 이런 일을 위해! 웹 사이트에서 내가 원하는 정보를 추출하는 웹 크롤링을 학습하고자 한다!
웹 크롤링 개요
웹 크롤링은 컴퓨터 소프트웨어 기술로 웹 사이트에서 자신이 원하는 정보를 추출하는 일련의 작업을 의미한다. 그리고 이를 수행하는 소프트웨어를 웹 크롤러라고 한다! 이를 개발하기 위해서는 작동과정과 그 구조, html의 구조, url의 구조에 대해 학습해야 한다.
- 웹 크롤링과 웹 크롤러
: 웹 크롤링? = 컴퓨터 소프트웨어 기술로 웹 사이트에서 자신이 원하는 정보를 추출하는 일련의 작업
: 웹 크롤러? = 웹 크롤링을 수행하는 소프트웨어
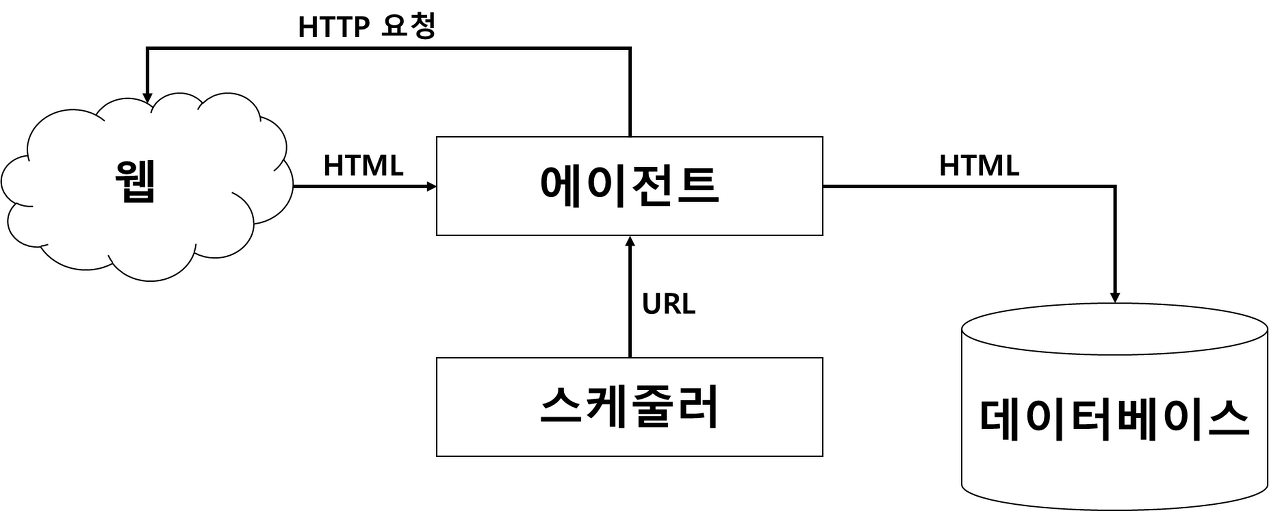
: 에이전트(agent) = 웹에 데이터를 요청하고 받아오는 역할
: 스케줄러 = 웹의 주소를 스케줄에 맞게 에이전트에게 전달하는 역할
: HTML = 웹에 있는 정보
- 웹 페이지와 HTML 기초
: 웹 페이지 혹은 웹 문서란 인터넷 상에 존재하는 문서로, 우리가 보고 있는 웹 사이트는 이러한 수많은 웹 문서로 구성된다! 그리고 이 문서를 작성하는데 사용하는 언어를 HTML 이라고 한다.
: 웹 크롤러는 HTML 코드로 표현된 웹 문서를 수집한다.
: HTML 코드는 여러 개의 요소로 구성되는데, 이 요소는 꺾쇠괄호 (<>) 로 툴러싸인 태그로 둘러쌓인다.
<tag> 요소 </tag>
: 태그는 하나 이상의 속성을 가질 수 있다!
<tag attribute = 'value'> 요소 </tag>
: 웹 크롤러가 수집한 HTML 코드에서 사용자가 원하는 요소만 가져오는 작업을 parsing 파싱이라고 부른다.
- URL과 파라미터
: URL? = 인터넷에서 어느 사이트에 접속하기 위해서 입력해야 하는 웹의 주소
: URL의 파라미터? = URL의 끝쪽에 물음표 뒤에 나오는 속성으로 효과적인 웹 문서 관리를 위해 사용
: 파라미터는 유사한 속성을 가진 문서들을 효과적으로 표시할 수 있도록 '속성 = 값' 들을 &로 연결한다.
예시1]
네이버 여성의류 - 원피스 홈페이지와 남성의류 - 티셔츠 홈페이지의 URL이 cat_id (카테고리 ID) 라는 속성까지는 같지만, 값만 다른 것을 볼 수 있다!
https://search.shopping.naver.com/search/category.nhn?cat_id=50000807
https://search.shopping.naver.com/search/category.nhn?cat_id=50000830
예시2]
네이버 영화에서 한편을 골랐을 때, 영화의 리뷰를 나타내는 url을 보면, 영화 코드(code)와 리뷰 페이지 번호 (page)라는 두 가지 속성으로 구성됨!
https://movie.naver.com/movie/bi/mi/review.nhn?code=96951&page=1
'PM이되고 싶어요!' 카테고리의 다른 글
| [프로덕트 기획] 카카오페이 PM의 데이터 활용 프로덕트 기획 (0) | 2022.03.31 |
|---|---|
| [추천 시스템] 데이터를 활용한 추천 시스템 기획, 타겟과 스포티파이를 통해 알아보기 (0) | 2022.03.23 |


댓글